Recently in Openmoko Category
February 10, 2010
The Mysterious Missing Milliamps
My new A7+ Freerunner arrived a few days ago. Before long I'd flashed it with the latest version of SHR-testing, made sure stuff worked, and moved my main SIM over to it. Then I set about installing all the most cutting-edge unstable userspace and 2.6.32 kernel stuff on the old A6 Freerunner ready to have some fun. But I quickly noticed that something wasn't right - it wouldn't charge properly. During my first Sunday hacking session, it didn't seem to be able to charge from a USB connection to my computer, and seemed to be getting quite warm to the touch as well.
The current_now sysfs node indicated that the device was using many hundreds of milliamps more current than it should have been. So much, in fact, that the current provided to it over USB by my laptop wasn't enough to charge the battery - with barely enough power to keep the thing running the battery slowly discharged. With the higher current provided by the mains charger, the battery would charge, but more slowly that normal. But this only seemed to happen with the 2.6.32 kernel.
Lots of discussion on IRC (mostly with DocScrutinizer) followed, and it emerged that one possibility was a short circuit in the uSD card slot. Sure enough: I'd moved my uSD card from the A6 to the A7+ Freerunner (since the new one didn't come with a card), leaving the A6's SD slot empty. On my device, some of the pins protruded up, perhaps enough to short out against the metal SD slot lid:

I cut a roughly 1x1.5cm rectangular piece of plastic from the packaging of some small halogen bulbs I'd bought the previous day, and put it into the slot as a "dummy". Testing again: no current drain. Dummy removed, the drain came back, and so on. The Doc had hit the nail on the head - the culprit was found!
But there was one more piece to the puzzle. Why didn't the drain seem to happen with the older 2.6.29 kernel? Turns out that a small detail had been left out from the kernel during an earlier merge. Because of this, the Glamo SD engine's power supply was left on all the time, when normally it should get switched off when no SD card was present. The resulting waste of a small amount of power became a huge power drain when the short circuit was added. Hopefully the SD electronics aren't too fried..
January 25, 2010
New Toys
So, I'm now the proud owner of a Lenovo Thinkpad T500 with WSXGA+ screen (1680x1050), 7200rpm HDD, Core 2 Duo, UK keyboard and 9-cell battery. Exactly to specification, and within budget :D
I've also ordered myself a second Freerunner. This was a bit less of a budgeted expense, but I have no real shortage of money at the moment (thanks to not drinking regularly). I realised that the reason for my recent lack of productivity wasn't time as such, rather the faff involved with switching into a very unstable environment for development then having to go back to a usable setup at the end of a "session". Developing in "sessions" like this seems to be a nice way to avoid getting anything done at all - I had the same problem at the start of my DRM work when we changed to Linux 2.6.29 from 2.6.24. It's much better to be able to work in a semi-continuous stream as time allows.
There's another reason for this purchase though. I'm affected strongly by the infamous Freerunner buzz problem in Germany, whereas I didn't notice it back in the UK. I was going to send my FR in to get both the buzz and #1024 (standby time) fixes done, but I've decided instead just to buy a new one with both fixes already. Then I'll use the new one day-to-day while my current one becomes a development platform, installed with all the latest and most unstable software I can find, so that I can stomp on the nastiest bugs with some degree of comfort.
And there's one more new toy: A 32TB RAID6 array with 4 optical fibre channel connections for storing and analysing our data on at work. All my analyses just went from being I/O limited to being firmly CPU bound..
November 15, 2009
Internal Memory Bottlenecks and Their Removal
While debugging something different late last night, I noticed some flags in one of Glamo's registers which looked interesting: FIFO settings for the LCD engine. This reminded me of an observation by Lars a few weeks ago that the LCD engine seems to conflict with Glamo's 2D engine on memory accesses, leading to slower performance of accelerated 2D operations when the screen is switched on. So I turned the FIFO up to "8 stages" (from 1) to see what happened. The result was much faster 2D operations - literally twice the speed!
At "8 stages", the price of this was that the display became jittery and unstable. However, the same speed improvement is seen at the "4 stages" setting. I've also seen some occasional artifacts with this setting, so I'm using 2 stages at the moment, where the speed is still right up there. I'll be testing some more and seeing if things can be tuned even more.
Because we don't make the maximum use possible of the 2D engine, this doesn't immediately translate into a huge increase in the UI speed. But the differences are very obvious with x11perf and some of my test programs. The program I showed in the screenshot recently jumped from 45-48fps right up to 95-98fps!
At "8 stages", the price of this was that the display became jittery and unstable. However, the same speed improvement is seen at the "4 stages" setting. I've also seen some occasional artifacts with this setting, so I'm using 2 stages at the moment, where the speed is still right up there. I'll be testing some more and seeing if things can be tuned even more.
Because we don't make the maximum use possible of the 2D engine, this doesn't immediately translate into a huge increase in the UI speed. But the differences are very obvious with x11perf and some of my test programs. The program I showed in the screenshot recently jumped from 45-48fps right up to 95-98fps!
November 13, 2009
"Look Ma, No Busywaits!"
When the CPU needs to do something
which depends on a result which the GPU is currently working on, it has to wait for the GPU to catch up. One of the biggest problems with the current architecture of xf86-video-glamo, both DRM and non-DRM versions, is that they do this waiting by spinning in a tight loop, each time checking the current status of the GPU, until it's caught up. This isn't great for a few reasons. It makes no use of the parallelism between the CPU and the GPU, so precious CPU time is being wasted while something more useful could be being done. If there's nothing else to do, then the CPU could be sleeping - reducing power consumption.
Most GPUs, including Glamo, have a mechanism for being a little smarter. The kernel can ask the chip to trigger an interrupt when a certain point in the command queue has been reached. When a process needs to wait, the kernel can send it to sleep and watch out for the interrupt. When it happens, the process can be quickly woken back up in a low-latency fashion, meaning that the process gets back to work with very little latency.
This week, I've been implementing this kind of thing for the Glamo DRM driver. It goes a bit like this:
Things aren't always so great. When the command sequence to be executed is very short, the overheads of fencing and scheduling become significant, and the overall rate drops. However, it shouldn't be too difficult to design some kind of heuristic to use busywaits as a low-latency strategy in such cases.
There are still a few problems to iron out. The fence mechanism seems to be able to fall out of sync with things, leading to processes waiting for too long (or even forever). But when it works, some things do seem to feel a little faster in general use.
Geeks may be interested in the actual code.
Most GPUs, including Glamo, have a mechanism for being a little smarter. The kernel can ask the chip to trigger an interrupt when a certain point in the command queue has been reached. When a process needs to wait, the kernel can send it to sleep and watch out for the interrupt. When it happens, the process can be quickly woken back up in a low-latency fashion, meaning that the process gets back to work with very little latency.
This week, I've been implementing this kind of thing for the Glamo DRM driver. It goes a bit like this:
- Process submits some rendering commands via one of the command submission ioctls.
- Kernel driver places rendering commands on Glamo's command queue.
- Process needs to wait for the GPU to catch up, so calls the wait ioctl.
- Kernel driver puts an extra sequence of commands, called a fence, onto the command queue. A unique number is associated with the fence. The number is recorded by the kernel.
- When the GPU processes the fence, it raises the interrupt and places a unique number into a certain register.
- The interrupt handler checks this number, and wakes up the corresponding process.
{kind=link}
Things aren't always so great. When the command sequence to be executed is very short, the overheads of fencing and scheduling become significant, and the overall rate drops. However, it shouldn't be too difficult to design some kind of heuristic to use busywaits as a low-latency strategy in such cases.
There are still a few problems to iron out. The fence mechanism seems to be able to fall out of sync with things, leading to processes waiting for too long (or even forever). But when it works, some things do seem to feel a little faster in general use.
Geeks may be interested in the actual code.
September 18, 2009
Glamo Mesa Driver
Having realised that most of the bugs I was chasing aren't actually my fault (see the to-do list), I've been allowing myself to work on the Mesa driver for Glamo. A rebase (sorry!) against the latest Git master branch of upstream Mesa was required to get some important DRI2 fixes, but now it works. I'm not going to go into much detail (I need to sleep), but enough of the initialisation and buffering stuff works that things can be drawn (using Glamo's 2D engine at the moment) and then put on the screen (front buffer) successfully. It's enough to draw a blue rectangle at the moment. Not much, but you wouldn't believe how much Stuff has to be working correctly for that to happen.
Actually, I expect that readers of the journal would believe exactly how much Stuff is involved...
Actually, I expect that readers of the journal would believe exactly how much Stuff is involved...
September 13, 2009
BFS Scheduler for Openmoko
I've done a backport of the BFS scheduler to the 2.6.29 kernel currently used by Openmoko. This is only for people who want to try something new and exciting before the official release of the forthcoming 2.6.31 kernel for Openmoko with our new repository layout (at which point the upstream BFS patch should apply cleanly).
It's hardly tested, and I might have screwed up the patch completely (I don't really know my way around these areas of the kernel), but here it is: BFS for Openmoko.
My experience was, despite reports of dramatic speedups on Android, that there wasn't a huge amount of difference compared to the conventional scheduler. Your experiences may differ, however.
It's hardly tested, and I might have screwed up the patch completely (I don't really know my way around these areas of the kernel), but here it is: BFS for Openmoko.
My experience was, despite reports of dramatic speedups on Android, that there wasn't a huge amount of difference compared to the conventional scheduler. Your experiences may differ, however.
August 25, 2009
KMS Font Rendering
Font rendering now works with the KMS Glamo driver. The problem was that a particular case of the trickiest EXA function ("ModifyPixmapHeader") wasn't handled correctly. The easy fix was to remove our implementation of that hook altogether and let EXA handle it on its own. To make this work properly, a new function (with similar but more limited functionality) had to be added to deal with the initialisation of the front buffer, like this.
So now, apart from whatever gremlins might be lurking deep in the code, the KMS driver should be on an even footing with the non-KMS version. Before getting on with Mesa and other such fun stuff, I'd still like to get to the bottom of the GEM hashtable corruption that seems to happen after a long time (more than a day) of operation. Additionally, there's a small issue with the width of the screen that happens with recent versions of X.org (1.6.1 and later at the very least), but that isn't specific to KMS.
For an up-to-date list of "things that are bothering me" like these, see this new page. Call it an unofficial project status page.
So now, apart from whatever gremlins might be lurking deep in the code, the KMS driver should be on an even footing with the non-KMS version. Before getting on with Mesa and other such fun stuff, I'd still like to get to the bottom of the GEM hashtable corruption that seems to happen after a long time (more than a day) of operation. Additionally, there's a small issue with the width of the screen that happens with recent versions of X.org (1.6.1 and later at the very least), but that isn't specific to KMS.
For an up-to-date list of "things that are bothering me" like these, see this new page. Call it an unofficial project status page.
August 20, 2009
KMS Progress, and Publicity
Listen to the sound of silence..
... that's the silence of intense concentration as things get exciting in the land of Glamo-DRI ...
Some welcome publicity (see Phoronix and Timo Jyrinki's Blog) has led to a burst of activity from me. It really does make a difference to know that people are interested in and excited by the project.
The current status is that the KMS Xorg driver is vaguely usable, apart from garbled font rendering and an occasional kernel oops. I'm tracking these down at the moment. A busy-wait is currently being used for synchronisation in the kernel, which isn't great (but no worse than the current system). This will get turned into a much more advanced interrupt-driver waitqueue system once I've worked the details out.
It turns out that the overheads involved with mmapping a pixmap's corresponding GEM object (every time X wants to draw something to it) have a fairly significant impact. X appears to be quite bad at batching operations together in a single period of access. Additionally, even tiny scratch pixmaps (which we have no hope of meaningfully accelerating) end up getting GEM objects as well. Optimisations are possible - we can leave each object mapped, and give the address back fast to X when it requests access. This is what the Radeon driver does in recent versions. Additionally, the latest Git version of the X.org server includes something called mixed mode pixmap handling, which is where EXA keeps the clearly unacceleratable pixmaps away from the driver and in the much faster system memory. The latter brings the speed almost up to what it was pre-KMS. I need to do some more experiments with the former.
... that's the silence of intense concentration as things get exciting in the land of Glamo-DRI ...
Some welcome publicity (see Phoronix and Timo Jyrinki's Blog) has led to a burst of activity from me. It really does make a difference to know that people are interested in and excited by the project.
The current status is that the KMS Xorg driver is vaguely usable, apart from garbled font rendering and an occasional kernel oops. I'm tracking these down at the moment. A busy-wait is currently being used for synchronisation in the kernel, which isn't great (but no worse than the current system). This will get turned into a much more advanced interrupt-driver waitqueue system once I've worked the details out.
It turns out that the overheads involved with mmapping a pixmap's corresponding GEM object (every time X wants to draw something to it) have a fairly significant impact. X appears to be quite bad at batching operations together in a single period of access. Additionally, even tiny scratch pixmaps (which we have no hope of meaningfully accelerating) end up getting GEM objects as well. Optimisations are possible - we can leave each object mapped, and give the address back fast to X when it requests access. This is what the Radeon driver does in recent versions. Additionally, the latest Git version of the X.org server includes something called mixed mode pixmap handling, which is where EXA keeps the clearly unacceleratable pixmaps away from the driver and in the much faster system memory. The latter brings the speed almost up to what it was pre-KMS. I need to do some more experiments with the former.
August 4, 2009
KMS X.Org Driver - Almost
The lack of posting on this subject recently has simply been because
I've, erm, been coding too hard. Here's a picture of the latest
situation: An X.Org driver running on a Neo FreeRunner, plus or minus a few "issues" which need ironing out:
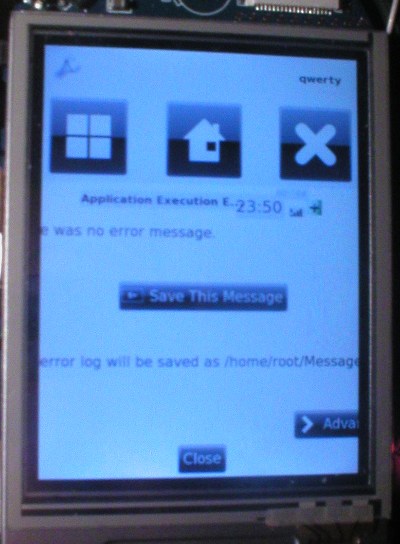 One of the more interesting parts of the recent hackathon has been the way GEM objects, held in Glamo's VRAM, are mapped into the address space of a process. In this way, a process can access something - such as an offscreen pixmap, the overall X framebuffer or later something such as a vertex list or texture object - in an unaccelerated fashion. Unaccelerated accesses have to happen at some point (we have to get data into Glamo at some point before more exciting accelerated things can be done with that data), so this isn't a bad thing and is quite important in the grand scheme of things. The way it works has a few steps:
One of the more interesting parts of the recent hackathon has been the way GEM objects, held in Glamo's VRAM, are mapped into the address space of a process. In this way, a process can access something - such as an offscreen pixmap, the overall X framebuffer or later something such as a vertex list or texture object - in an unaccelerated fashion. Unaccelerated accesses have to happen at some point (we have to get data into Glamo at some point before more exciting accelerated things can be done with that data), so this isn't a bad thing and is quite important in the grand scheme of things. The way it works has a few steps:
One of the more interesting parts of the recent hackathon has been the way GEM objects, held in Glamo's VRAM, are mapped into the address space of a process. In this way, a process can access something - such as an offscreen pixmap, the overall X framebuffer or later something such as a vertex list or texture object - in an unaccelerated fashion. Unaccelerated accesses have to happen at some point (we have to get data into Glamo at some point before more exciting accelerated things can be done with that data), so this isn't a bad thing and is quite important in the grand scheme of things. The way it works has a few steps:- The process calls our ioctl, DRM_IOCTL_GLAMO_GEM_MMAP, passing the handle of the GEM object it's interested in mapping.
- The kernel generates an offset, and records it in a list next to the GEM handle. The DRM device, /dev/dri/card0, behaves as if it were a huge file, sections of which correspond to GEM objects that have been mapped. The offset gets returned to the process.
- The process calls mmap() with its file descriptor (corresponding to /dev/dri/card0), the offset and size of the object.
- The core bits of kernel generate a new virtual memory area (VMA) for the newly mmap'd area, and pass control to DRM.
- DRM looks up the offset in its list, and - if found - sets up some flags on the VMA. Notice that nothing has actually used the true physical memory address of the VRAM yet.
- The kernel returns the start address of the new VMA to the process, which tries to access its contents.
- The access to the memory generates a page fault, which gets passed back through the kernel and eventually ends up in our DRM driver. Finally, we set up the page tables so that the virtual address given to the process actually corresponds to the VRAM inside Glamo.
July 20, 2009
OpenMooCow Using ALSA Directly
I've now got bored enough of SDL problems (as described here) to start work on a version of OpenMooCow which uses ALSA directly. Development can be found in the "alsa" branch, here.
It basically works, but still uses SDL only for loading the WAV file and converting the sample rate of the sound. After removing the SDL dependency altogether, it'll be released as version 0.5.
It basically works, but still uses SDL only for loading the WAV file and converting the sample rate of the sound. After removing the SDL dependency altogether, it'll be released as version 0.5.